
usertest_create_template_archive.ipynb) and importing your materials (import.ipynb).



 WE1S Workspace
WE1S Workspace
Our core tools are included in a Workspace that can be used modularly or in a workflow sequence to collect, manage, analyze, topic model, visualize, and perform other operations on texts. The Workspace includes the tools described below for topic modeling and visualization, whose modules (sets of related Jupyter notebooks and associated tools that we call our “templates”) are released under the open MIT license.  Available in our Zenodo deposit (“WhatEvery1Says (WE1S) Workspace Template,” doi: 10.5281/zenodo.5034712) and our GitHub site (we1s-templates).
Available in our Zenodo deposit (“WhatEvery1Says (WE1S) Workspace Template,” doi: 10.5281/zenodo.5034712) and our GitHub site (we1s-templates).
Topic Modeling Tools
Important Jupyter notebooks in our Workspace include those for creating and running a topic modeling project—setting up the project; importing, exporting, or managing texts; pre-processing texts; performing various analyses (such as counting documents or terms); topic modeling; and conducting topic model diagnostics. Available in our Workspace (see above).
Visualization Tools
Our Workspace also includes Jupyter notebook modules for generating interactive visualizations of topic models. We call our suite of original or adapted visualization interfaces our Topic Model Observatory. Visualization interfaces in the Topic Model Observatory useful for general purposes—exploring a topic model and its underlying materials with various degrees of freedom in looking into topics, words, and documents—include Dfr-browser, TopicBubbles, and pyLDAvis. More specialized interfaces include Metatata&D, GeoD, and DendrogramViwer. (See our Topic Model Observatory Guide.) Available in our Workspace (see above).
Tools for Collecting the Web & Social Media
We also make available our Chomp—a set of Python tools designed to find and collect text from webpages on specified sites that contain search terms of interest. Unlike other web scraping tools, Chomp is designed first and foremost to take a wide sweep—working at scale and across a variety of different platforms to gather material. Available in our GitHub (we1s_chomp).
For collecting from Twitter, we offer our TweetSuite, a set of tools used to collect data from Twitter and prepare it for topic modeling. See also our research blog post on our methodology of collecting materials from Reddit. Available in our GitHub (tweet-suite).
Interpretation Protocol (for Topic Models)
We developed a topic-model “interpretation protocol” that declares standard instructions and observation steps for researchers using topic models. Our goal is a transparent, documented, and understandable process for the interaction between machine learning and human interpretation. (See WE1S Bibliography of Interpretability in Machine Learning and Topic Model Interpretation.) We do not to assert a definitive topic-model interpretation process (because this will be different depending on the nature of projects, materials, resources, and personnel). We declare our interpretation protocol to serve as a paradigm to be adapted, improved, and varied by others. The protocol takes the form of survey-style questionnaires that step researchers through looking at a topic model and drawing conclusions from it.
Our Interpretation Protocol is a workflow that is modularly customizable. For example, a researcher can start by intitially exploring a model (modules 1-2) and then choose chains of other modules for specific research purposes—e.g.,”Analyze a topic” followed by “Analyze a keyword.”
We implemented the Interpretation Protocol for our project as a modular series of Qualtrics questionnaires providing instructions to researchers about what to observe in a topic model and what questions to answer (in note fields that follow the principles of Grounded Theory human reporting on data). We provide our questionnaires not just as Qualtrics files (importable by others with institutional access to Qualtrics) but also as Word documents.
- Live Qualtrics surveys (WE1S developers only)
- QSF files (for import into Qualtrics and adaptation by other users with institutional access to the Qualtrics platform)
- Word versions (.docx) (most accessible version of the Interpretation Protocol; useable "as is" or may be adapted by others)
- Interpretation Protocol home
- Flowchart (diagram of Interpretation Protocol modules)
Manifest Schema
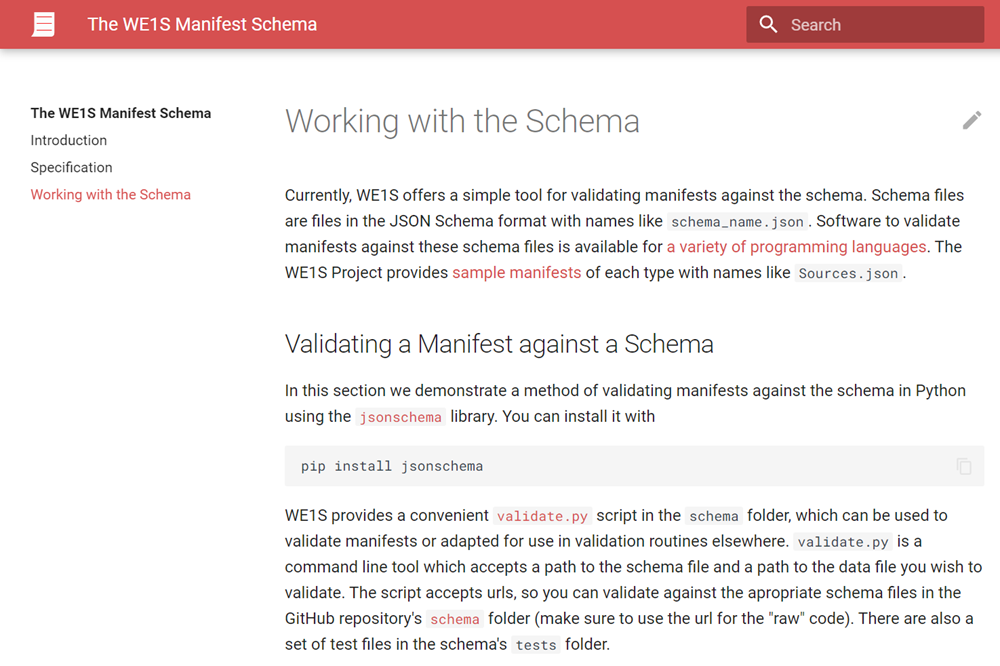
To document our resources, tools, and workflow in a way that is both transparent to humans and computationally tractable, we created a “manifest” schema for our work that could be adapted by other digital humanities projects. The WE1S manifest schema is a set of recommendations, examples, and validation tools for the construction of manifest documents for the WE1S project. We use the manifest schema to define metadata for individual documents, collections, sources, and corpora, as well as topic modeling projects. (See definition of manifest in a computing sense.)
WE1S manifests are JSON documents that describe resources. They can be used as data storage and configuration files for a variety of scripted processes and tools that read the JSON format. Manifests may include metadata describing a publication, a process, a set of data, or an output of some procedure. Manifests can also describe software tools, processes, and workflows, as well outputs such as result data, information visualizations, and interactive interfaces. Their primary intent is to help humans document and keep track of their workflow. Available in our GitHub (manifest).
