


Also: "relatively few Americans agree with a variety of negative statements about the field" (See The Humanities in American Life, p. 3.).
That’s also what they say.

![]()


In particular, we used computational methods to help us study vast numbers of articles and social media posts mentioning the humanities.
What everyone says about the humanities or anything else in the media, after all, is different from what anyone says one-on-one. The media is a reverberating echo chamber producing storylines through broadly impactful, but complicated, rhetorical scenarios—such as when a politician interviewed for a story addresses the generic taxpayer (or
We focused on the U.S. to start with a manageable scope of materials, and also because our researchers—based at the partner institutions of U. California, Santa Barbara; California State U., Northridge; and U. Miami—have a poorer understanding of the social, economic, political, and cultural contexts of the media and the humanities in other nations. (We invite others to use our materials, methods, and tools and software to extend our research internationally.)
Why search for documents containing the literal word "humanities" and related words? We did so not because we think these terms by themselves cast a net over all the humanities. In the vast sea of public discourse, the humanities also appear under the names of "literature," "history," or other specific kinds; and the humanities are name-dropped everywhere in discussions of particular people, books, intellectual movements, controversies, organizations, events, and so on. The humanities are also surprisingly pervasive in media coverage of common life and death events—for example, in wedding announcements and the obituaries of everyday (not just famous) people. There is no predefined, bounded set of media documents for studying public discussion of the humanities.
So we aimed for a strategically chosen subset of materials mentioning the literal word "humanities" (plus sometimes other terms) on the hypothesis that we could thus capture a good swathe of examples on both sides of the line between a general concept of the humanities and specific kinds of humanities, and between wider public discussion of the humanities (as when "humanities" comes up in relation to words like "literature," "history," and people, books, organizations, etc.) and more specialized academic discourse on the humanities (as when universities call a group of disciplines "the humanities").

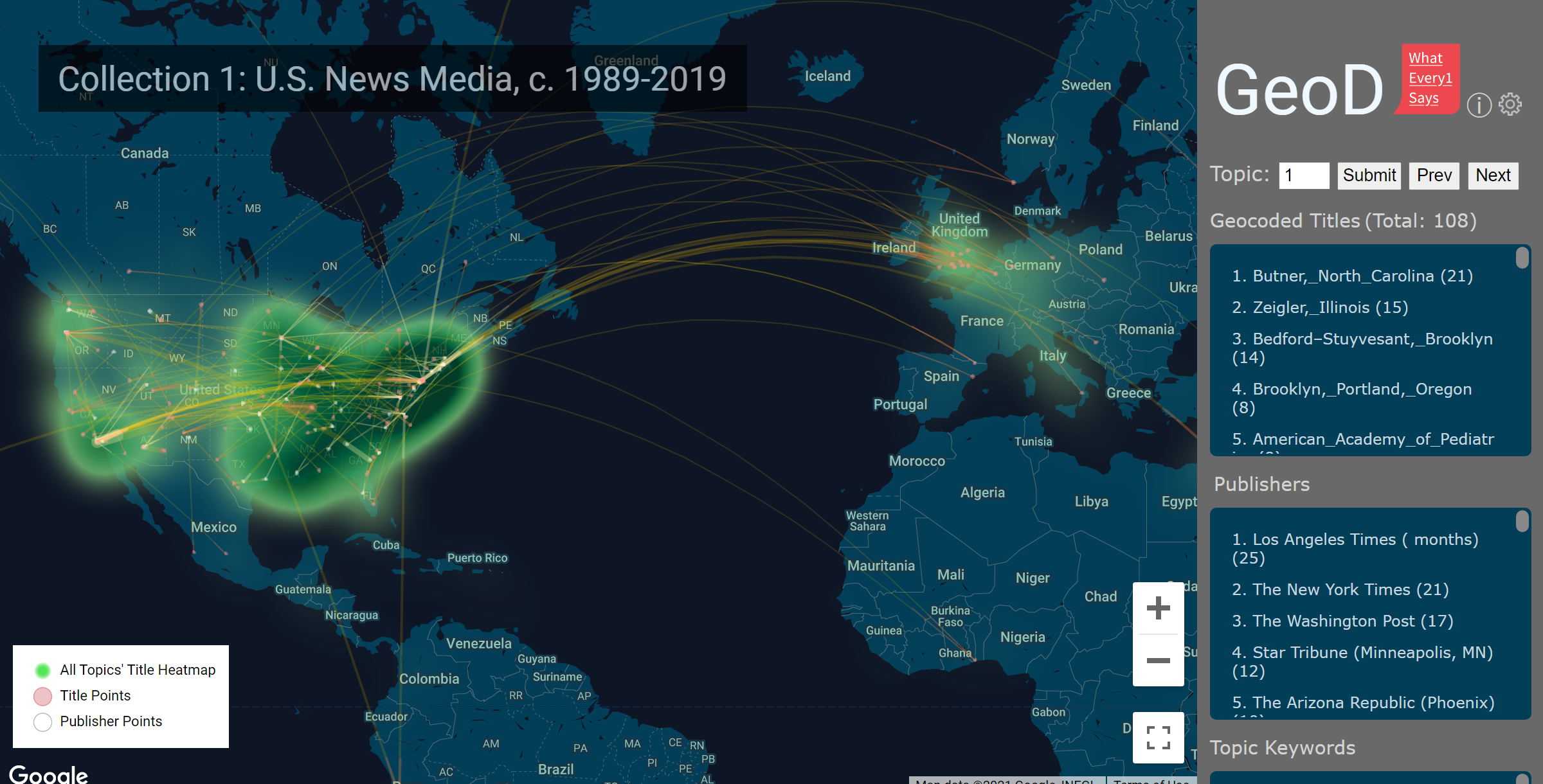
WE1S Collection 1

We feature nineteen of these collections on our Collections & Topic Models page, where we describe each and make them available for other researchers in the form of their word frequency counts, computational models and visualizations, and other derived or generated data (but, unfortunately, no readable text due to copyright or licensing constraints except for texts we directly gathered from public and open sources).
So that other researchers can fully benefit from the data we harvested and processed from the materials we studied, we deposited our full datasets in the Zenodo repository operated by CERN to promote "open science." These datasets (six in total) hold all the data and metadata from which our "collections" were extracted for modeling. For example, Collection 1 is a subset of data from our humanities_keywords dataset. (See our Datasets page for more information and access to our Zenodo deposits.)
![]()

What's a Topic Model?

A WE1S Topic Model
Collection 1 in WE1S TopicBubbles visualization

Topic modeling works by discovering in large numbers of texts what appear to humans to be thematically coherent “topics.” It does so by analyzing the statistical co-occurrence of words. That is, it finds out which words tend to appear together in a set of documents (and in individual texts).
An article about a political election, for example, might frequently use words naming a nation’s capital city (e.g., "London”) together with such other words as "Parliament." In a topic model, a list of the most frequent words in such a co-occurring group of words can often suggest that the articles sharing many of such words participate together in a "topic"—in this case, one that might be labeled something like "British government."
It also shows which specific documents participate strongly in a topic (or in several topics at once, since an article mentioning "London" might talk partly about politics but also partly about economics because London is also a financial capital).
Topic modeling thus not only helps find gross patterns but guides human readers to specific examples of documents to examine closely because of their statistical association with a topic. Such guidance is an improvement on cherry-picking examples anecdotally or because they fit a researcher’s preconceived "hunch" about what is going on.
Materials: Our collections can be downloaded as “bags of words.” (This means that except for open-access documents or social media, we are constrained by copyright to sharing original documents only as word frequency counts and other "non-consumptive use" data, which can be used for computational modeling methods such as topic modeling but not for ordinary human reading).
Tools: You can download our Workspace of Jupyter notebooks and other tools for performing topic modeling our texts (or your own) and then for visualizing models in the interactive interfaces of our Topic Model Observatory. The Workspace is available in a Docker “containerized” form [soon to be released] so that you can reproduce everything on your own computer and run it. We also make available our Topic Model Interpretation Protocol—standard instructions and observation steps for researchers using topic models.
(See WE1S GitHub and Zenodo deposits for access to tools we have so far released under the open MIT license.)
![]()
Topic Model Observatory
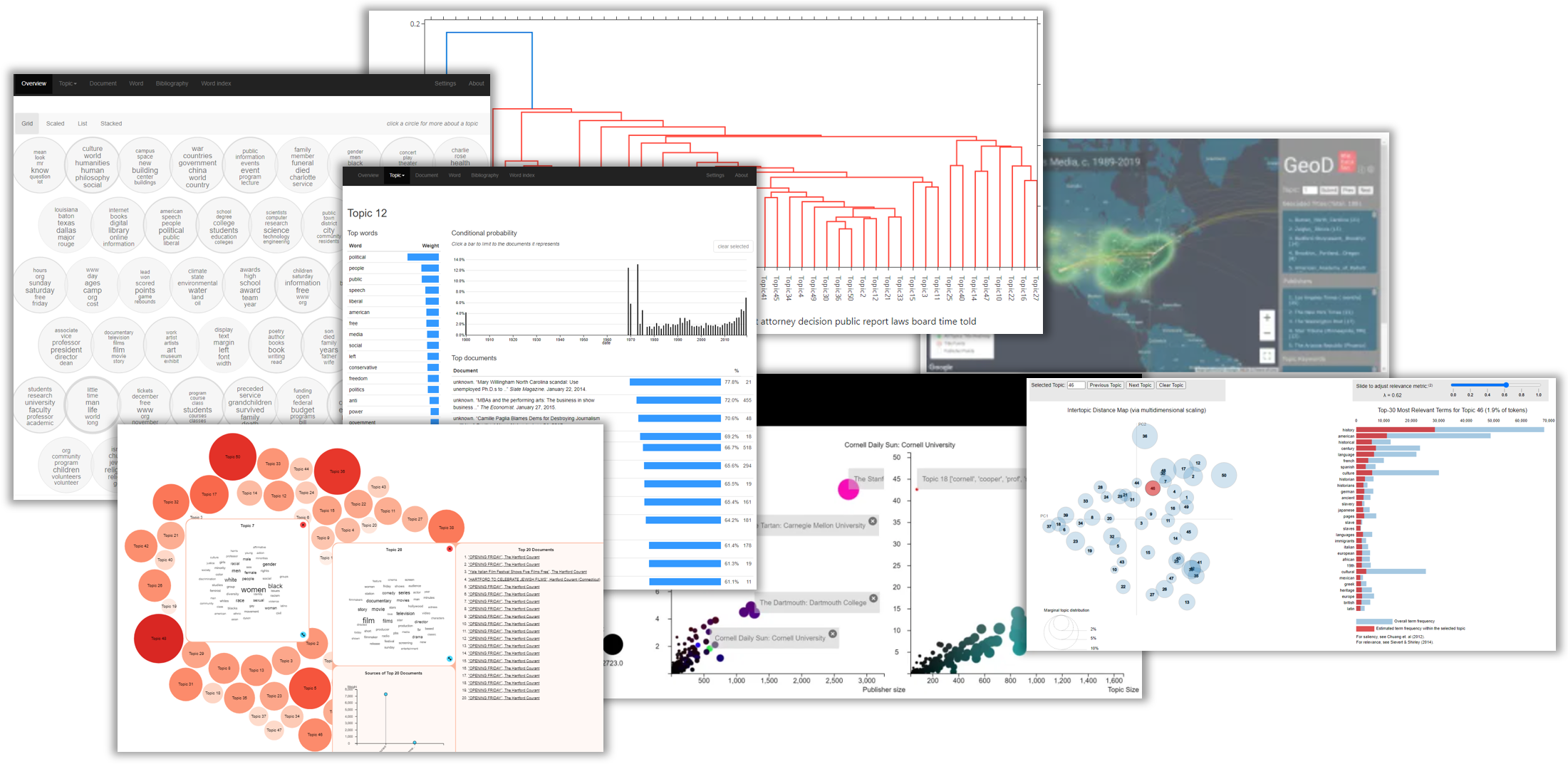
While topic modeling may guide humans to particular articles for “close reading,” there is still an inescapable sense for humans of great distance---as if seeing things from outer space, because that is how far away we have to go to see “what everyone says.”
That's why we called our suite of adapted and original interactive visualization interfaces for exploring data models our "Topic Model Observatory."
So besides closely reading articles that our topic models pointed us to, we added an up-close human touch. We surveyed students and others, and met them in focus groups in which we discussed their views of the humanities.
Our “human subjects research”—as it is called by the “institutional review boards” at our universities, which for ethical reasons must approve research involving people—was small-scale and local by comparison with the Humanities Indicators U.S. survey. We conducted it at two of our three campuses partnering on the WE1S project: U. California, Santa Barbara, and U. Miami.
But the human subjects research was illuminating. The purpose was to give us a gut check on what the media says about the humanities. We needed to hear what students and others near us were saying. Our local and small-scale results helped us better understand the wider media discourse by seeing the humanities from various specific perspectives—for example, the student viewpoint (including that of our project institutions' many first-generation college or first-generation immigrant students).

![]()

Some of the one-page cards reporting on WE1S project's "Key Findings." (See all our Key Findings to date.)
|

Article by Lindsay Thomas and Abigail Droge in Journal of Cultural Analytics, 2022
|

Daedalus journal cover
|

First post in @WE1Sproject Twitter thread about project running from January 21 to March 30, 2022
|
WE1S's key findings are presented in our "cards" reporting system. These are one-page explanations in public language (instead of academic discourse) that include summaries, examples, and links to our underlying research as well as other resources. On our Key Findings page, for example, cards appear grouped under “humanities crisis,” “value of the humanities,” “broader profile of humanities in society,” “humanities and social groups,” “humanities and science,” “students and the humanities,” “humanities and social media,” “humanities and ordinary life,” and “humanities funding.” Along with other cards we wrote on project materials, methods, tools, and recommendations, our key finding cards are the public face of a reporting system that scales up to long-form reports, research blog posts, and publications and talks.
Longer publications and talks by WE1S participants offer syntheses of the project's findings (see bibliography of WE1S Publications, Talks, and Selected Posts). Our most important scholarly publications to date include the following:
- Lindsay Thomas and Abigail Droge,
- “The Humanities in Public: A Computational Analysis of US National and Campus Newspapers,” Journal of Cultural Analytics 7, no. 1 (2022): 36–80
- “What We Learned About the Humanities from a Study of Thousands of Newspaper Articles,” Journal of Cultural Analytics, May 24, 2022, 139–44
- Alan Liu, “What Everyone Says about the Humanities,” MLA Newsletter 54, no. 1 (2022): 1, 4–5.
- Alan Liu, Abigail Droge, Scott Kleinman, Lindsay Thomas, Dan C. Baciu, and Jeremy Douglass, “What Everyone Says: Public Perceptions of the Humanities in the Media,” Daedalus (2022).
Watch also for our posts on social media. From January 21 to March 30, 2022, we posted on our @WE1sproject Twitter account a stream (one or several posts a day) reporting on our project and its results.
See our Key Findings
(More to be added as research continues.) Watch also for articles and essays to come providing higher-level conclusions and reflections on our findings.
- The Humanities "Crisis"
- Value of the Humanities
- Broader Profile of the Humanities in Society
- Humanities and Social Groups
- Public discourse as represented in the media treats humanists as authorities on cultural discourses about race, racism, and ethics. (KF-3-1)
- In both mainstream and student journalism, universities appear to be dominated by liberals in ways that impair intellectual diversity (KF-4-2)
- Contributions of the academic humanities to thought on gender and sexual identity have little impact on media coverage of these issues (KF-3-5)
- Humanities and Science in the Media
- The humanities appear to the public to be siloed in universities (unlike the sciences) (KF-5-2)
- The public likes to take its science with objects (and the humanities have none) (KF-5-4)
- The media hides core values of science behind a veil of “data-speak” (KF-5-5)
- The sciences stand out for the public as distinct fields (unlike the humanities, which blur together as just “academics”) (KF-5-7)
- Student journalists see positive opportunities for interdisciplinary collaboration between the sciences and the humanities (KF-8-5)
- Students and the Humanities
- Students Writing about Education Value Cognitive Flexibility and “Soft Skills” Associated with the Humanities and Liberal Arts (KF-8-1)
- In student newspapers, parents appear to be supportive instead of demanding (KF-8-7)
Students writing in campus newspapers argue that the humanities help us engage meaningfully with human nature and society. (KF-4-5) - Students imagine a bleak future without the humanities (survey result) (KF-8-9)
Students are twice as likely to think others stereotype them based on their majors than that they stereotype others (survey result) (KF-8-2) - Students’ personal and academic commitments to the humanities don’t always align; extracurriculars provide flexible space for engagement (survey result) (KF-8-3)
- Humanities and Social Media
- The Humanities and Ordinary Life
- The humanities are the art of ordinary life (KF-5-3)
- Humanities Funding
- The media covers only a fraction of the humanities areas the NEH was established by the U.S. Congress to support (KF-7-2)
- The media covers funding for humanities research, but pays almost no attention to funding for humanities teaching (KF-7-4)
- Humanities funding for K-12 primary and high-school education receives the least media coverage (KF-7-3)
![]()
And such is what it would mean to teach the humanities too in ways that innovatively weave together their values and practices with those of other areas of education and broader society. (See the examples of courses we developed and our rich stream of blog posts about them in our Curriculum Lab.)
Here are our recommendations (still in-progress). We also make them in the form of one-page "cards": Calls to Action and Calls to Communication cards.
The full potential of our "cards" reporting system is realized in the Research-to-Action Toolkits we are beginning to build, which—snap together our modular cards of different kinds (for collections, methods, tools, key findings, calls to action, and calls to communication). These are kits for understanding and advocating the vital role of the humanities in today's world.
We invite others to use our data and tools (or to use our tools on other materials) to expand our grasp of "what everyone says" about the humanities, and to add to our findings and recommendations for ensuring that the humanities go forward as full partners in society—past, present, and future.


![]()
Explore our website
About | Team | Advisory Board | Blog | Our Research | Our Recommendations | Our Curriculum Lab | WE1S Bibliography
A networked view of our resources in their interrelationships (selected).
