
Introduction
The WE1S Identity and Inclusion team (of which we are a part) is focused on research outputs centered on how gender, sexuality, race, and ethnicity factor into humanities discourse. Our core questions of interest include: How are different gender and ethnic groups positioned in relation to the humanities in public discourse? What kind of conversations do these groups hold about the humanities? Are there discrepancies between how these groups position themselves in relation to the humanities and the ways in which other groups position them in relation to the humanities? Do “identity-focused” sources focus on different topics or issues compared with the sources collected in the WE1S primary corpus?
This past year, we were thinking about how we could create new outputs for the project that aren’t necessarily focused exclusively on data collection, and to imagine methods and visualizations beyond topic modeling that can help us answer research questions about how various social groups and identities are positioned in relation to the humanities. Word embeddings based on a corpus of college mission statements constitute one of these outputs.
We are interested in analysis of college mission statements because a mission statement is one of the most prominent, public-facing documents in which a university conveys its core values, objectives, and areas of focus. This carefully curated language, therefore, is a public representation of a university, and reflects what is most important to a given school. This interest also grew out of our work mapping Historically Black Colleges and Universities (HBCUs), Hispanic-Serving Institutions (HSIs), Tribal Colleges, and Women’s Colleges. We are curious about whether these colleges and universities that are affiliated with given ethnic, racial, and gender identities use different language in their mission statements in comparison to colleges and universities that are not institutionally affiliated in this way. Our hypothesis is that identity-affiliated colleges and university mission statements include more language about diversity and inclusion and tend to spotlight to a greater extent the groups that they represent and serve.
In addition to exploring this question, we also aim to explore other questions using our mission statements corpus and word embeddings in the coming months, including the following questions. What terms and values connect given universities, and how do these terms connect given schools? Which terms appear most frequently across a corpus of mission statements, and what does this say about mission statements as a genre? Which terms are unique to a given school or university, and what does this reveal about a school? When, where, and how do terms related to the humanities appear in these mission statements? When, where, and how do terms related to the STEM fields appear in these mission statements?
We collected a sample corpus of university mission statements from identity-affiliated institutions (HBCUs, HSIs, Tribal Colleges, and Women’s Colleges). Su details her methodology for producing the word embeddings below.
Note before proceeding: The best way to follow the methodology for creating the word embeddings of the mission statements is to view the Jupyter notebook on my GitHub in `Word2Vec for Mission Statements.ipynb` at https://github.com/sburtner/we1s-mapping, which should be publicly available. This document will serve to outline some of the key steps and findings from that Jupyter notebook, followed by some analysis of the initial results.
Quick Background
Like many tutorials have noted, it is good practice for anyone interested in learning about word embeddings to first read the articles by the authors of word2vec, who introduced two forms of the method (Mikolov, 2013) and then gave key extensions to improve embedding accuracy (Mikolov, 2013). Of course, there are now numerous tutorials online that break down what word embeddings are in plain English (and with little math, if that’s not your thing.) Three that I have relied heavily upon for my own work has been this tutorial that was hosted on kaggle, the gensim tutorial on GitHub, the gensim documentation, and a workshop Su took with Bo Yan and the Collaboratory at UCSB in Spring of 2018[1].
The great advantage of word embeddings as a digital humanities tool is that we can find phrases of words and words that are functionally similar (or dissimilar). The motivation behind learning the representation of words as vectors is that words inherently possess some type of joint probability of occurring together, and the authors of the original word2vec introduced a neural architecture that attempts to construct the distribution from which these joint probabilities are drawn. The two methods involved in word2vec are Continuous Bag of Words (CBOW) and Skip-gram, which are nearly ubiquitous in providing the foundation for all other word embedding models.
The architecture of the Skip-gram model in word2vec continues to be the preeminent technique for learning word embeddings for many reasons. word2vec extended the original Skip-gram model by introducing a hierarchical softmax function, negative sampling, and subsampling of frequent words, which allow for the possibility of learning vector representations for millions of words and phrases in a highly efficient manner. The flexibility of word2vec can be seen by the numerous subsequent papers from other researchers (e.g. dna2vec, GloVe, node2vec, etc.) who have adopted the word2vec model and modified it for specific use cases. For the purposes of creating word embeddings from the mission statements, only the original Skip-gram model is used.
Methodology
The process of creating the word embeddings breaks down into a few simple parts (again, following along with the Jupyter notebook is paramount for seeing what is going on.)
Create the corpus:
- Generate a random list from our identity-focused universities and colleges
- Scrape the internet for the mission statement pages of the schools chosen
- Copy all statements into a CSV (include any specific stop words)
Create the model:
- Build the model, following the Python and gensim code provided and setting thoughtful parameters (which I can’t claim to have done well)
- Train the model using the Python code provided
Explore the model:
- Construct the word embeddings image using dimension reduction
- Test word similarity (or dissimilarity) using the functions provided by gensim
Now, what questions can we explore using the word embeddings of our mission statements? In the following section are some examples for the implementation of Skip-gram.
Preliminary Findings
Word Embeddings

Exploratory questions
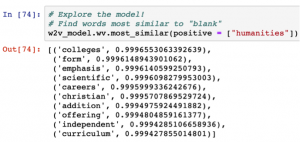
1.) Which words are most similar to “humanities” in our corpus?
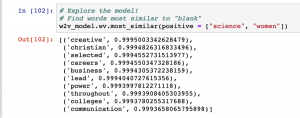
2.) Which words are most similar to “science” and “women” in our corpus?
3.) How similar is “science” to “humanities” in our corpus?

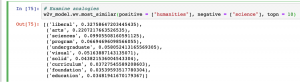
4.) Which words are the most similar to “humanities” and dissimilar to “science” in our corpus?
5.) Which word doesn’t belong, conceptually, in the set of words given?

Discussion
Obviously, this model could be better.[1]For example, the very last method, “doesnt_match,” gives us a result that we would not expect when saying “arts” is the least likely to be included in a list of “liberal humanities arts science” (though maybe not?) Other results are equally thought-provoking. It is interesting to see “emphasis,” “careers,” and “independent” closely tied to “humanities,” as well as “scientific,” for some reason. Unsurprisingly, “engineering” is close to “science,” but “gender” is as well. The words “liberal,” “arts,” and “sciences” are most similar to “humanities” and dissimilar from “science” (again, a weird morphological inaccuracy here.)
With improvements in the model, including expansion of the corpus, there are several worthwhile questions that we plan to explore. Using the “doesnt_match” function, we might be able to see which values words appear together or not. With the similarity function and the ability to test dissimilarity, we can explore how different genders are positioned in the media with reference to the humanities (such as in ‘positive = [“women”, “humanities”]’.)
