
Representing Gender, Sexuality, Race, and Ethnicity in the WE1S Corpus
Report by Giorgina Paiella
Final Version Created June 2018
Citation
Paiella, Giorgina. “Diverse Populations News Sources.” WhatEvery1Says Project, http://we1s.ucsb.edu. July 3, 2018. http://we1s.ucsb.edu/diverse-populations/.
1. Overview
What is your area(s) of focus?
I am collecting sources that address the WE1S project’s interest in how issues of gender, sexuality, race, and ethnicity factor into representations of the humanities. These questions include the following: How are different gender and ethnic groups positioned in relation to the humanities in public discourse? What kind of conversations do these groups hold about the humanities? Are there discrepancies between how these groups position themselves in relation to the humanities and the ways in which other groups position them in relation to the humanities?
I am mainly—though not exclusively—focusing on North American publications that are targeted toward, or take up as their focus, a variety of ethnic, racial, linguistic, geographic, and gender groups, as well as a spectrum of sexual identities. While most of these publications are English-language publications, several are Spanish-language publications, and many are published in bilingual editions (including Cherokee language, Italian, French, etc.). I am keeping track of these multilingual sources, which may in the future become part of the WE1S subcorpora. Because topic modeling can only be conducted on one language at a time, Spanish-language sources, for example, may be used for Spanish-language topic modeling experiments.
Many of these publications are aimed at multicultural identities (for example, Italian American, Polish American, Scandinavian American, etc.), so their geographic coverage is often international.
Why is this area of focus important to the WE1S corpus?
This area of focus is important to the WE1S corpus because it allows the project to answer questions regarding gender, sexuality, and ethnicity that are core areas of interest and inquiry. Because the project is investigating the ways in which the humanities are represented in public discourse, we must address the ways in which various groups view themselves in relation to the humanities and how public discourse positions these groups in relation to the humanities (which may, very well, differ). Collecting from these sources will allow us to examine how these publications—and, by extension, the groups that they represent or address as their audience—discuss the humanities. It also allows us to explore similarities and differences among these publications and how they treat the humanities. Other questions that these sources can help the project answer include: How are the humanities positioned in these publications? In what contexts are the humanities discussed? What investments do paper owners, publishers, and various groups and identities have in the humanities?
Furthermore, these publications are important because they are targeted at groups that are not always the focus audience of mainstream publications. In addition to spotlighting some of these lesser known or niche papers, it is important to incorporate multicultural and multilingual perspectives and publications that represent a spectrum of gender and sexual identities. Granting this visibility to minoritized perspectives allows for an exploration of how communities represent themselves in print while also acknowledging these groups and publications as contributors to—and participants in—public discourse.
2. Source Scoping Process
How have you been selecting sources for the WE1S corpus? (e.g. collecting from particular databases, using “impact” lists, etc.)
I have primarily been selecting sources for the WE1S corpus from two ProQuest databases, ProQuest Ethnic NewsWatch and ProQuest GenderWatch. ProQuest Ethnic NewsWatch is a full-text collection of over 340 publications and 2.5 million articles that addresses many ethnic identities. ProQuest GenderWatch offers over 250 full-text titles and 219,000 articles from academic, radical, community, and independent presses targeted toward gay, lesbian, bisexual, and transgender (GLBT) communities.
Both databases include a variety of publication types, including newspapers, magazines, and journals. Before filling out the Google facet collection form, I combed through the full title list of both databases, selecting out only the newspaper and magazine sources, which are the two publication types that comprise the WE1S main corpus. Scholarly journals, conference papers, dissertations, trade journals, and press journals that are available in both databases would be a fascinating contribution to the WE1S subcorpora, and I hope that we can collect from these sources in the future.
If you are using external lists to guide your selection of sources, include links here and indicate who produced them, for what purpose the list was produced, and any potential bias issues involved.
I am using ProQuest Ethnic NewsWatch and GenderWatch databases, which are hyperlinked above. These databases are the most comprehensive databases for publications aimed at ethnic communities and gender groups and identifications. While no database can achieve absolute representativeness, these databases continually add publications and aim to include sources from as many groups and presses as possible.
3. Corpus Representativeness
How representative do you think your corpus is? (“Representativeness” can be interpreted and addressed in a number of ways, so tailor it to be most productive for your area.)
I think that my corpus is representative of many gender and ethnic groups. My goal in collection (which is still in progress) is to include at least one publication for each ethnic and gender group that is available in the databases to ensure that all groups for which we have publication access are present in the corpus. I am aiming for both depth and breadth in my corpus, including multiple publications for given ethnic and gender groups (when available) to offer a variety of perspectives from within a given community, while also collecting from as wide a variety of groups as possible.
What challenges in achieving representativeness have you encountered?
Because I have been collecting from the ProQuest GenderWatch and Ethnic NewsWatch publications, I haven’t faced many challenges in achieving representativeness, but the representativeness of my corpus is defined by the representativeness of the databases. That said, I am confident that these are the most comprehensive databases for publications geared toward ethnic and gender groups and will allow us to build a representative corpus.
As stated above, these databases include publication types other than magazines and newspapers. As we proceed with assessing the representativeness of our corpus and delineating the subcorpora, collecting from these other sources will increase the representativeness of the corpus and ensure that the greatest feasible number of perspectives is being represented.
In terms of linguistic representativeness, the publications in my corpus are not always available in the bilingual editions that they are often originally published in, so we are not able to fully represent those languages. Some sources are also translated, which presents issues related to translation, preservation, and loss. The WE1S project, however, is primarily looking at English-language publications, and the added limitation of topic modeling experiments being unilingual makes these issues understandable and manageable.
Provide a tally breakdown of the various facets of sources in your area of focus that WE1S is considering as possible measures of overall corpus “representativeness” (for example, by source or media type, nationality, region, political orientation, identification with specific racial, ethnic, and gender audiences, etc.)
This is the tally breakdown for the sources that I have added to the Google facet collection form thus far for my area of focus. While I have divided the sources by ethnic/racial audience and gender/sexuality audience and their respective publication counts to keep track of the sources from each respective database, there is, of course, some overlap among categories (for example, a publication on African American women, could be listed in either category). I have preserved how these publications self-identify for the greatest specificity and accuracy possible, but there is also overlap among certain ethnic categories (for example, a Finnish American publication would also be classified as Scandinavian American). I will continue to think about productive ways to acknowledge these overlaps while also preserving how these publications choose to represent themselves.
Ethnic/Racial Audiences
- African American: 18
- African American Women: 1
- Alaska Natives: 1
- Arab American: 1
- Arabic: 1
- Armenian American: 2
- Asian American: 1
- Black studies: 1
- British, mixed-race, African, and African-Caribbean women: 1
- Canadian Aboriginal: 1
- Ethiopian: 1
- Filipino American: 1
- Finnish American: 1
- General race issues/communities of color: 2
- German American: 1
- Haitian: 1
- Hmong-American: 1
- Indian: 1
- Italian-American: 1
- Irish: 1
- Irish American: 1
- Jewish American: 7
- Lebanese American: 1
- Middle Eastern: 1
- Moroccan American: 1
- Muslim women: 1
- Native American: 10
- Polish-American: 1
- Russian/Russian American: 1
- Scandinavian: 1
- Scandinavian American: 1
- Spanish language: 4
- Ukrainian American: 1
- Vietnamese American: 1
Gender/Sexuality Audiences
- Catholic women: 1
- Feminist: 7
- Gay men: 1
- General LGBTQIA community: 5
- Lesbian/Bisexual women: 2
- Transgender: 1
- Men and Masculinities: 1
- Gender and Environment: 1
- Women engineers: 1
What challenges or difficulties have you encountered in the source selection or collection process? Do you anticipate any challenges emerging from your work going forward?
The greatest difficulty that I have encountered in the collection process is the widely differing amount of public information available on various sources. While some publications will have a lot of information documented not only on their respective websites, but also other sites (including Wikipedia, Chronicling America, etc.), other sources will have little to no information available. This results in a discrepancy in facet completeness from source to source—while I have been able to fill out all of the facets in the Google form for some sources, many facets are left blank for those with little archival information, which means that we know less about these sources, including circulation numbers and ownership information.
I have noticed that there is less information available for more niche papers, small presses, and certain ethnic groups. An interesting question that arises from this issue is which publications are documented in greater detail and why, which opens up into fascinating political questions about what is archived, what is left out of the archive, and what is considered worthy of archiving. ProQuest GenderWatch and Ethnic NewsWatch promote the visibility of these publications by including them in databases for preservation and use. These databases, however, do not always provide all of the metadata that we need to fill out our Google collection form (and sometimes, this is the only information available for a given source). See the following screenshot for an example of the information that is provided for V Magazine in Ethnic NewsWatch:
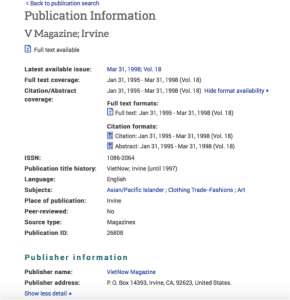
Related to questions of archiving, my research has revealed that certain papers have gone bankrupt or face difficulty in maintaining archives because of lack of funding, support, or governmental attempts to shut papers down (this has particularly been the case for some Native American publications historically). In addition to including these publications in research databases, libraries and organizations are working to preserve these records. One notable example is the Tundra Times, an Alaskan Native publication. While the paper ceased publication in 1997, The Tuzzy Consortium Library in Barrow, Alaska is working to preserve the voice of the paper through the Tundra Times Photograph Project, an initiative to scan and index the photograph collection of the Tundra Times newspaper.
Another problem that has emerged in my research has been finding information on smaller publications that share a name with larger, better-known publications. One example is V Magazine (see figure one above for publication information in Ethnic NewsWatch). While this publication is a Vietnamese/Vietnamese-American publication published in Irvine, California, it shares the name of an American fashion magazine published in New York. There is a lot of information available for the latter publication, but little else besides the Ethnic NewsWatch database publication information record available for the former.
5. Research Scan
Conduct some preliminary research on the questions or challenges that you provided in sections three and four.
Have other scholars reflected on these issues? Are there publications that address these problems? Has research been conducted on how to overcome these challenges or at least acknowledge them productively?
While I have not yet found publications that address the specific corpus collection issues that I have outlined in relation to the WE1S project, there are many articles and projects that address issues of gender, sexuality, race, and ethnicity in the archives and issues of preservation and exclusion. See below for a bibliography of a few sources that discuss issues of power and identity in the archive:
Kim, David J. and Jacqueline Wernimont. “‘Performing Archive’: Identity, Participation, and Responsibility in the Ethnic Archive.”Archive Journal, April 2014. http://www.archivejournal.net/essays/performing-archive-identity-participation-and-responsibility-in-the-ethnic-archive/
Teaching Gender with Libraries and Archives: The Power of Information, edited by Sara De Jong and Sanne Koevoets, Central European UP, 2013.
