
Created by Samantha Wallace (posted Aug. 2, 2018; last revised Aug. 2, 2018) [Documentation of the spreadsheet below is in draft form.]
An Excel spreadsheet implementing an equation for thee optimal number of topics in a WE1S topic model. (Excel is used because it is easier to make trend lines in it than in Google Sheets.) Download the spreadsheet: best-fit-for-number-of-topics
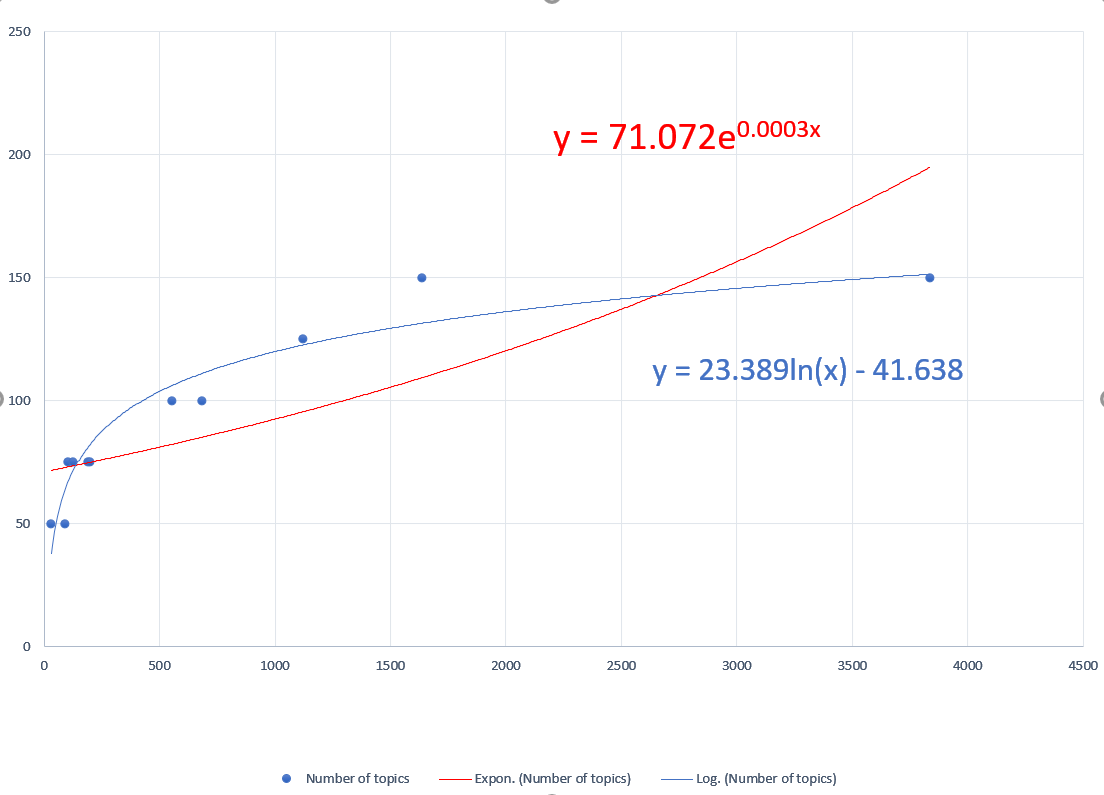
Explanation of the equation from the developer: “In order to predict the optimal number of topics, I began to qualitatively assess what number of topics in a topic model created less junk topics and more coherent topics. I created multiple topic models, with different numbers of topics, for a single corpus with a set number of clean articles. Once I found the best topic model, I input the data into an Excel spreadsheet using the number of clean articles in a corpus as the input (x) and the optimal number of topics for that corpus as the output (y). Once I had enough data, I created a scatter plot graph from this data and inserted a best fit trend line.
I began using exponential equation trend lines to predict the optimal number of topics. I incorrectly predicted that exponential equations would keep the number of topics in control, since a linear trend line could potentially lead us to having 800 topics for an 8,000 article corpus. As I began to input data collected from experimenting with large size corpora, I realized that logarithmic equations would be more accurate for a best-fit trend line. The logarithmic equation has a smaller slope, and the slope gets smaller as x (input data) increases, which means that as we begin to work with very large corpora the optimal number of topics will remain manageable (170 topics for 8,000 articles) and smaller corpora will have enough topics to interpret (75 topics for 250 articles).”
Download the spreadsheet: best-fit-for-number-of-topics
